Data is Everywhere. The growth of data has been exponential in the last few years and organizations are facing an uphill task managing their data to ensure they have a 360-degree view of their business to remain competitive. It is therefore a constant endeavor to build data platforms that ensures agility, scalability and quicker insights as a part of their digital transformation journey. Besides volumes, varying data types also make it increasingly difficult for data warehouses to capture new content. Unstructured information coming in from streaming data, social media sites and IoT devices alongwith the structured information from ERP and CRM solutions needs to get synchronized to provide a holistic view. Higher expectations from users, rapid globalization of economies and data democratization is making Data Lakes popular!
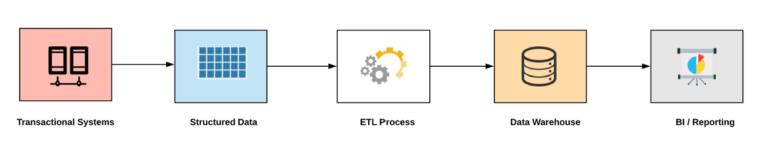
Legacy Data Architecture: Data Warehouse
Modern Data Architecture: Data Lake
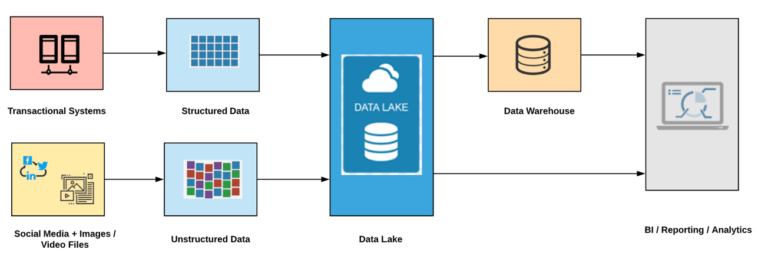
The legacy architecture shows the way Data Warehouses were built and most of the organizations will also consider building Data Marts if they want data to be organized according to their Line of Business. Data Lakes on the other hand were built by ingesting different data types and could store much bigger volumes (Petabytes / Zettabytes) of data.
Reference Architecture of a Data Lake
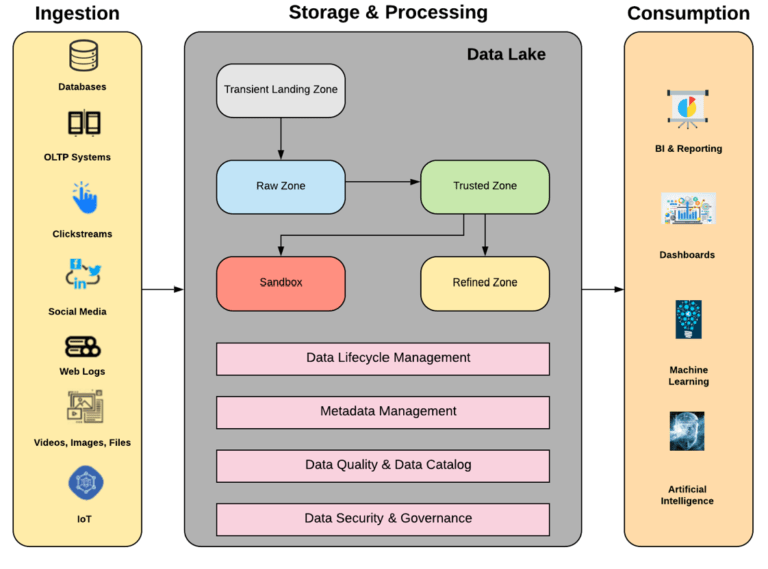
Architectural Considerations for Building Data Lakes
The three components in the Data Lake include: Ingestion, Storage & Processing and Consumption. It is difficult to come up with a one-size-fit-all architecture for a Data Lake. It depends on multiple factors related to the business problem the organizations ought to solve. Some considerations are given below:
- Data Ingestion: Real-time or batch
- Storage Tier: Raw vs Trusted, Refined etc. Can have many more zones based on business needs
- Metadata Management: Technical (form and structure), Operational (quality and lineage) & Business (significance to the user)
- Data Security & Governance: Access to sensitive data and policies & standards followed
- Data Quality & Catalog: Cleansed data that is easy to search
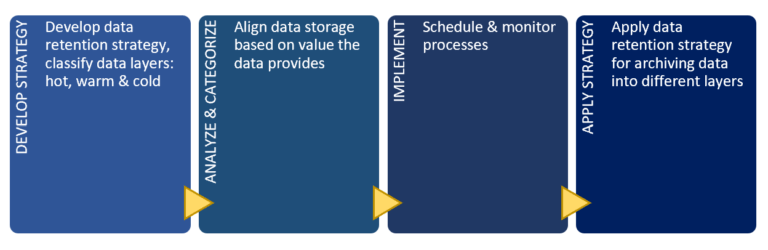
- Data Lifecycle Management: Categorization of data into hot, warm and cold zones based on frequency of usage
Now let us look at some of the above areas in more detail and how it impacts the data lake architecture:
Transient Landing Zone:
A predefined, intermediate location where data from source systems will be stored before moving into the raw zone. Here the data is organized by source systems and has following functions:
- Aggregation: Consolidates data from multiple sources, tags data with metadata to determine source of origin and generates timestamps
- Validation: Basic validation checks on the data that has arrived involving MD5 checks and record counts
- Cleansing: Removing or updating invalid data, effectively auditing and tracking data issues
- Archiving: Data not so critical can be archived instead of processing it further
Essentially this zone checks on data integrity issues during acquisition of data that is either pulled or pushed from the source systems. Incase of batch processing all data coming at periodic intervals can be stored in a file. For real-time processing, events are streamed into the system, validated in the zone and consumed by the subsequent tiers to execute processing on it.
Raw Zone:
This zone contains raw data in its original form and is made available to any downstream systems that require such data with minimum enrichment for analytical processing. Deep validation of the data should be performed and the data is watermarked for lineage and tracking. Metadata is captured for all data types in the raw zone. This typically should include when the data was ingested, who initiated the ingestion and where the data originated from.
Trusted Zone:
Building of Trusted zone and any other additional zones typically depends on business needs. You may not want to provide raw zone access to all employees within the organization as the data is sensitive and warrants restricted usage. Data such as Personally Identifiable Information (PII), Personal Health Information (PHI) can be tokenized and relevant data can be stored in trusted zone.
Refined Zone:
Data from Trusted zone can be further enriched according to the different Lines of Business (LOBs) within the organization such as Finance, HR, Manufacturing etc. to store relevant data in this zone and employees within each department can be provided role-based privileges to access such data.
Discovery Sandbox:
Data from trusted zone moves into discovery sandbox for data wrangling, discovery and exploratory analysis by different users and data scientists.
Data Lifecycle Management (DLM):
Even though Data Lake means we can store huge volumes of data, does not mean that we will create a data swamp by storing anything and everything in it. DLM ensures there are rules governing what can and cannot be stored. The value of data over longer periods of time tends to decrease and risks associated with storage increases and hence DLM ensures only appropriate and meaningful data is stored by defining policies the organization follows for hot, warm and cold data. E.g., data for last seven years can be considered cold and archived.
Metadata Management:
Metadata is extraordinarily important to managing your data lake, whether manually collected or automatically created during data ingestion, metadata allows your users to locate the data they want to analyze. A well-built metadata layer allows organizations to harness the potential of the data lake by accessing the correct data to perform analytics.
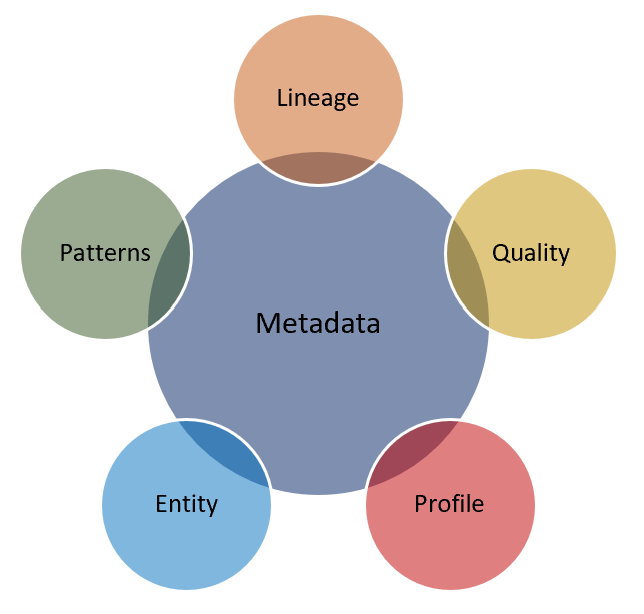
Metadata can be classified into three groups:
- Technical Metadata: captures the form and structure of each data set e.g., text, images, JSON etc.
- Operational Metadata: captures the lineage, quality, profile and provenance e.g., when the data arrived, where are they located, where did they arrive from, the quality of data etc.
- Business Metadata: captures what the data means to the end users e.g., names, descriptions, tags, quality, masking rules etc.
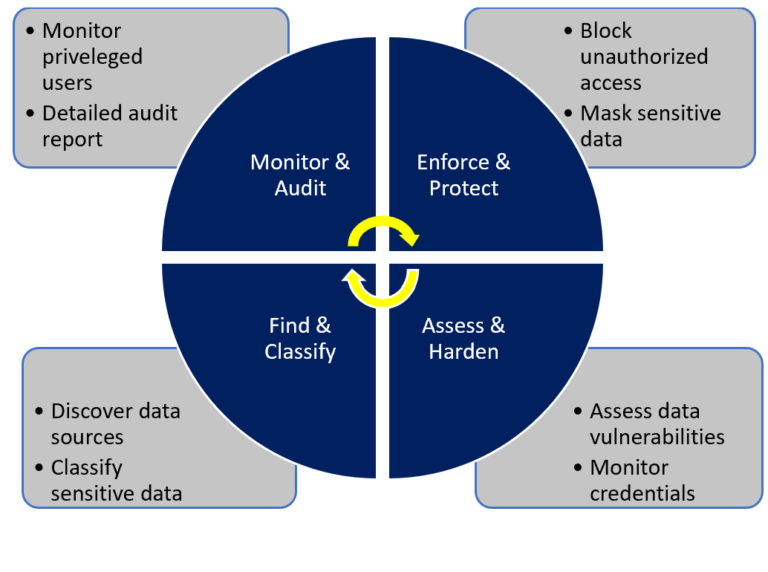
Data Security and Governance:
The security layer essentially ensures authentication and access control to data assets and artifacts. Governance on the other hand provides a mechanism for creation, usage and tracking of the data lineage across various tiers of the data lake so that it can be combined with the security rules.
If the data consists of both transaction and historical data, alongwith customer, product, finance as well as data from third-party sources, this ensures that each subject area has applicable level of security.
Both on-premises and cloud data lake ensure that users are authenticated before they access the data or compute resources.
Data Quality:
Here the data is checked to understand how good it is or the percentage of bad records that are present by means of ingestion from different source systems. This helps in planning data cleansing and enrichment approaches. Data Quality is essentially a combination of the below:
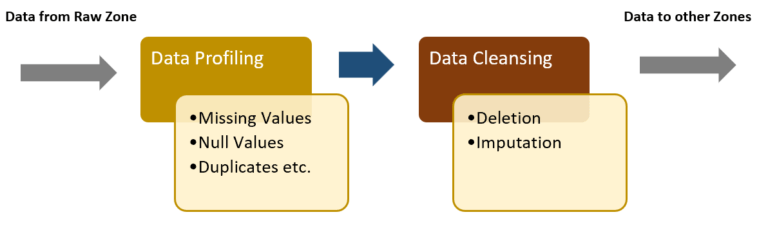
In short, you can also set data cleansing standards that are applied as the data is ingested in order to ensure only clean data makes it into the data lake and is useful for future analysis.
Data Catalog:
Sometimes you need to see what data sets exist in the data lake, the properties of those data sets, the ingestion history of the data set, the data quality, and the key performance indicators (KPIs) of the data as it was ingested. You should also see the data profile and all the metadata attributes, including those that are business, technical, and operational. All these things need to be abstracted to a level to where the user can understand them and use that data effectively—this is where the data catalog comes in. Your management platform should make it easy to create a data catalog and to provide that catalog to business users, so they can easily search it—whether searching for source system, schema attributes, subject area, or time range. With a data catalog, users can find data sets that are curated, so that they do not spend time cleaning up and preparing the data. This has already been done for them, particularly in cases of data that has made it to the trusted zone. Users are thus able to select the data sets they want for model building without involving IT, which essentially shortens the analytics timeline.
Data Modernization
Now the bigger question is if Data Lakes are so popular can they completely replace Data Warehouses or both can co-exist. Modern data architecture talked about data lake feeding into a data warehouse and reporting happening from both the data platforms. Today, we have quite a few Cloud data warehouses such as Snowflake that can accept data, both structured and semi-structured from any data store such as an Amazon S3 and provides quicker insights. Data warehouses are particularly popular for low latency reporting and insights as compared to data lakes. Different organizations may have varying business requirements and at the same time would want to leverage the investments made in the past. We came across a situation where one of our customers had implemented a Data Warehouse and was using it for the last 10 years. With growth of data volumes, their data warehouse could not handle additional data loads, there existing archival and restore process was manual and posed a substantial risk. The customer was looking for a solution with longer data retention periods for historical data that has been accumulating for many years and in turn would enable them to perform Adhoc Analytics with Data Mining. Data modernization was the answer to their problem!
We implemented an on-premises data lake and moved them to a hybrid data warehouse and Hadoop environment to dramatically increase storage capacity, improvise processing speed and reduce costs. This was done without impacting their upstream / downstream business systems and enhancing the end-user experience. The solution enabled them to do wider range of analytics and that too quickly. They saved millions of $$ in their capex, reduced their Total Cost of Ownership (TCO), increased their storage capacity multi-fold and the architecture implemented helped them capture unstructured content such as customer feedback, emails etc. directly into their data lake with reporting / dashboarding happening from both the platforms. A schematic of their architecture is shown below:
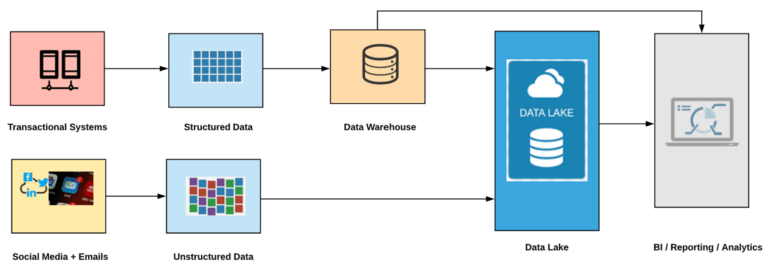
In a nutshell, organizations implementing data lakes have seen immense benefits with only one caution exercised; doing it through experts who can bring in all their experience and adopt best business practices. To be truly valuable a data lake cannot be a silo but must be one of several platforms in a carefully considered end-to-end modern enterprise data architecture. This will enable organizations not only to build a data lake that is open and extensible but extremely easy to integrate with their other business-critical platforms.
Parag Penker
GLOBAL VICE PRESIDENT – TECHNOLOGY (BIG DATA, DATA WAREHOUSING & BUSINESS INTELLIGENCE)
Parag is heading the Big Data, Data Warehousing and BI initiatives across the USA, India, Middle East and Africa. Parag carries more than 25 years of experience in the IT Industry and has PMP, Oracle Hyperion and SAP Supply Chain Certifications to his credit.