As I had mentioned earlier, the challenge organizations face, is to derive value from the data platforms implemented.
We were approached by a healthcare company who wanted to build few technical and business use cases on their existing Oracle Big Data Lake implementation. They were struggling to ingest varying data types both structured and unstructured and build automated data pipelines by directly accessing data from third party source systems as well as data coming in the form of APIs. The challenge was also in ascertaining the quality of data, making meaningful transformations and storing it in respective zones with a defined purpose. The business use case was more on generating quicker insights through reporting and dashboarding and later using advanced ML algorithms that could facilitate critical decision making.
Our role essentially was divided into three broad areas:
- Providing Technical and Advisory Services to assess the current data lake implementation and suggest improvements to optimize the existing cluster, recommendations on technology stack to be used, validate the security measures, creating benchmarks to improve I/O utilization and ensuring the changes recommended meet industry best practices.
- Creation of automated data ingestion pipelines both for structured and streaming data by writing scripts in Java, Python etc. to pull the data directly from the source systems and APIs in acceptable formats (e.g., converting XML, JSON to CSV wherever required)
- Finally, generating intelligent insights by integrating data from different data sources to create reports and dashboards enabling the organization to take informed decisions.
The Target state architecture was designed based on careful evaluation of their business pains and use case objectives and is shown below:
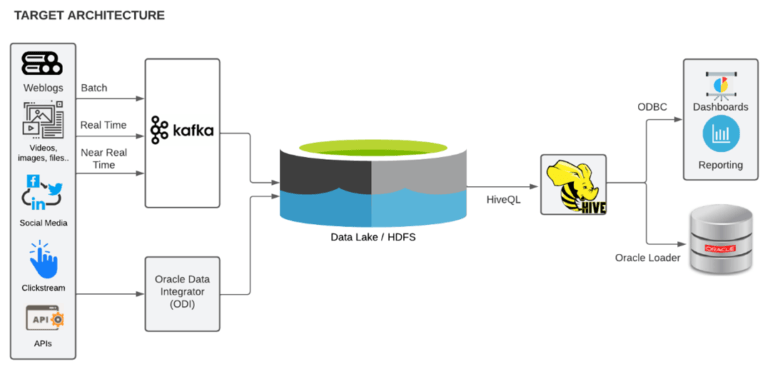
Our work involved a thorough study on the architecture and configuration including data sources, connections, storage & compute strategy, security, sensitive data handling, zones, system design of various components used and throughput considerations before making recommendations and working closely with the customer’s IT team to get it implemented.
While optimizing the cluster for performance we also provided inputs on the ideal technology stack to be used in implementing different use cases. The consideration was not only to expedite the creation of ingestion pipelines but also ensure quality transformations were carried out on raw data, before making it available for future insights.
Besides the above and as indicated earlier, we were also tasked for implementing three platform use cases and one business use case during the engagement. The first use case was pertaining to analyzing web logs and data from Google Analytics APIs to carry out loyalty analytics. As per the architecture schematic, Kafka was used for receiving batch and streaming data from source systems and processing was carried out using Spark before storing it in the data lake (HDFS).
The second and third use case was more on extracting operational data / survey data coming in the form of APIs again from third-party source systems and those were converted to CSV from their original format of JSON and XML and analyzed using PySpark. This data was essentially extracted using Oracle Data Integrator (ODI) as we can see above in the target state architecture.
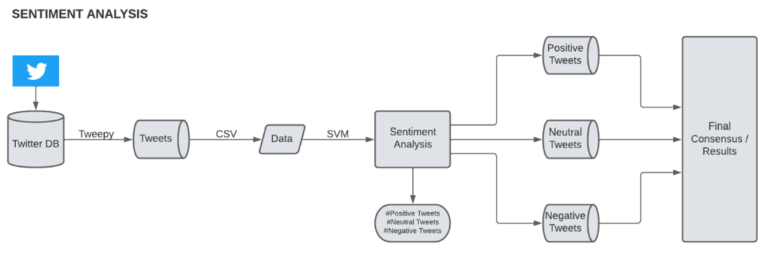
The business use case was all about extracting data from social media site. Twitter was used in this case as they wanted to analyze tweets and later perform Sentiment Analysis to make meaningful inferences. We used Tweepy to access Twitter’s API to extract data, parsed the results to a csv file and created visualizations in Power BI. Later for carrying out the Sentiment Analysis on the filtered tweets, we had a choice of using one of the advanced ML algorithms either Support Vector Machine (SVM) or Naïve Bayes as a part of Natural Language Processing (NLP) to derive final consensus.
A schematic of how the data is accessed from Twitter to do Sentiment Analysis is given below:
To summarize, this case study talks about how the healthcare organization was able to derive significant benefits by rearchitecting their data platform, leveraging the utilization substantially within their technical and business teams followed by successful implementation of their use cases over a short time. It is important to note that while organizations are looking at ways and means to modernize their business platforms due consideration needs to be given to develop a solution that is agile, provides shorter time to insight and can scale up by stitching complex ecosystem components together!
Parag Penker
GLOBAL VICE PRESIDENT – TECHNOLOGY (BIG DATA, DATA WAREHOUSING & BUSINESS INTELLIGENCE)
Parag is heading the Big Data, Data Warehousing and BI initiatives across the USA, India, Middle East and Africa. Parag carries more than 25 years of experience in the IT Industry and has PMP, Oracle Hyperion and SAP Supply Chain Certifications to his credit.