
Organizations are modernizing their data architectures which ensures agility increases, time to insight as soon as data gets generated is shortened and importantly it provides a scalable platform for storage and processing. Data lakes are becoming a corner stone in their journey towards digital transformation.
An Enterprise Data Warehouse (EDW) is used to store important business data. The EDW is designed to capture the essence of the business from other enterprise systems such as customer relationship management (CRM), inventory, and sales transactions systems, and allow analysts and business users to gain insight and make important business decisions from that data. But new technologies—including streaming and social data from the Web or from connected devices on the Internet of things (IoT)—is driving much greater data volumes, higher expectations from users, and a rapid globalization of economies. Organizations are realizing that traditional EDW technologies can’t meet their new business needs. As a result, many organizations are turning to Data Lakes !
A data lake is a central location in which to store all your data, regardless of its source or format. It is typically, although not always, built using Hadoop. The data can be structured or unstructured. You can then use a variety of storage and processing tools—typically tools in the extended Hadoop family—to extract value quickly and inform key organizational decisions. Because all data is welcome, data lakes are an emerging and powerful approach to the challenges of data integration in a traditional EDW, especially as organizations turn to mobile and cloud-based applications and the IoT.
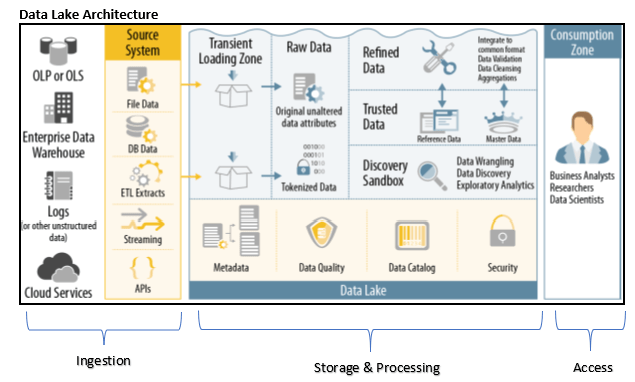
Functions of a Data Lake
Ingestion
- Scalable / extensible to capture both batch and streaming data
- Provide capability to business logic, filters, validation, data quality, routing etc. business requirements
Storage & Retention
- Depending on the requirements data is placed into a repository
- Metadata management
- Policy based Data retention is provided
Processing
- Processing is provided for both batch and near-real time use cases
- Provisioning workflows for repeatable data processing
- Provide late data arrival handling
Access
- Dashboard and applications that provide valuable business insights
- Data is made available to consumers using API, MQ feed, DB access
The data is first loaded into a transient loading zone, where basic data quality checks are performed using MapReduce or Spark by leveraging the Hadoop cluster. Once the quality checks have been performed, the data is loaded into Hadoop in the raw data zone, and sensitive data can be redacted so it can be accessed without revealing sensitive or vulnerable data.
Most importantly, underlying all of this must be an integration platform that manages, monitors, and governs the metadata, the data quality, the data catalog, and security. Although companies can vary in how they structure the integration platform, in general, governance must be a part of the solution.
Other Functions
Metadata Management
Metadata is extraordinarily important to managing your data lake. An integrated data lake management platform makes metadata creation and maintenance an integral part of the data lake processes. This is essential, as without effective metadata, data dumped into a data lake may never be seen again. Metadata is critical for making sure data is leveraged to its fullest. Whether manually collected or automatically created during data ingestion, metadata allows your users to locate the data they want to analyze. It also provides clues for future users to understand the contents of a data set and how it could be reused.
Data Catalog
Sometimes you need to see what data sets exist in the data lake, the properties of those data sets, the ingestion history of the data set, the data quality, and the key performance indicators (KPIs) of the data as it was ingested. You should also see the data profile, and all the metadata attributes, including those that are business, technical, and operational. All of these things need to be abstracted to a level to where the user can understand them, and use that data effectively—this is where the data lake catalog comes in. Your management platform should make it easy to create a data catalog, and to provide that catalog to business users, so they can easily search it—whether searching for source system, schema attributes, subject area, or time range. With a data catalog, users can find data sets that are curated, so that they don’t spend time cleaning up and preparing the data. This has already been done for them, particularly in cases of data that has made it to the trusted area. Users are thus able to select the data sets they want for model building without involving IT, which shortens the analytics timeline.
Data Governance
An important part of the data lake architecture is to first put data in a transitional or staging area before moving it to the raw data repository. It is from this staging area that all possible data sources, external or internal, are either moved into Hadoop or discarded. As with the visibility of the data, a managed ingestion process enforces governance rules that apply to all data that is allowed to enter the data lake. Governance rules can include any or all of the following:
Encryption
If data needs to be protected by encryption—if its visibility is a concern—it must be encrypted before it enters the data lake.
Provenance and lineage
It is particularly important for the analytics applications that business analysts and data scientists will use down the road that the data provenance and lineage is recorded. You may even want to create rules to prevent data from entering the data lake if its provenance is unknown.
Metadata capture
A managed ingestion process allows you to set governance rules that capture the metadata on all data before it enters the data lake’s raw repository.
Data cleansing
You can also set data cleansing standards that are applied as the data is ingested in order to ensure only clean data makes it into the data lake.
Enterprises are also looking ahead. They see that to be truly valuable, the data lake can’t be a silo, but must be one of several platforms in a carefully considered end-to-end modern enterprise data architecture. Just as you must think of metadata from an enterprise-wide perspective, you need to be able to integrate your data lake with external tools that are part of your enterprise-wide data view. Only then will you be able to build a data lake that is open, extensible, and easy to integrate into your other business-critical platforms.
Reporting – Dashboarding & Business Use Case Implementation
Once data has been provisioned in the Data Lake, you will then need to start deriving value of the data from the platform that has been implemented. This is the time when Data Analysts / Data Scientists will derive value of the data either from the Refined Zone or Sandbox to meet business goals.
Various third-party reporting tools such as Tableau, QlikView, Power BI etc. can be used for reporting & dashboarding purposes. The tools can connect through an ODBC Connection with the on-premise or cloud data lake to display appealing visualizations as shown below:

Data Scientists however can utilize the data from any of the zones to implement a business use case. One of the common use cases is that of Customer 3600 which is described below:
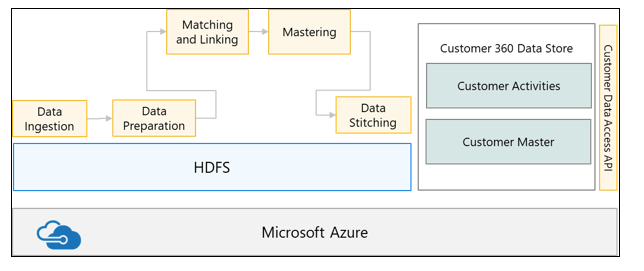
Customer Master Data from disparate data sources is ingested into the Data Lake, transformed as per business rules, mastered using Machine Learning (ML) techniques to form golden records, stitched with data coming in from transactional systems to form a Customer Data Hub.
Parag Penker
VICE PRESIDENT – TECHNOLOGY
Parag is heading the Big Data, Data Warehousing and BI initiatives across the USA, India, Middle East and Africa. Parag carries more than 25 years of experience in the IT Industry and has PMP, Oracle Hyperion and SAP Supply Chain Certifications to his credit.



